Text Extraction Engine
Very commonly a requirement of extracting data from a PDF/image presents itself. When individuals receive PDF documents they come in a variety of formats. Some have been system generated and thus text is generally embedded directly in the PDF, while some are scanned documents and are generally (various quality) image files embedded in the PDF. In all scenarios, while PDF viewers contain some tools to extract text, they do not output text in a consistent method across various documents. This makes it difficult to automate the extract of detail from documents. On the image side, there is generally no structural information available about the content and there is no embedded text available.
The Text Extraction Engine provides users with a screen to upload documents to the service. After uploading, documents will be processed via a number of AWS Lambda services coordinated via AWS Step Functions. PDF documents have text extracted via Poppler, while PDF files with embedded images or image files are processed via Tesseract. Custom Lambda layers have been created containing a build of each of these services (See here for more information). After the document has been successfully processed the end user is able to download the output as JSON.
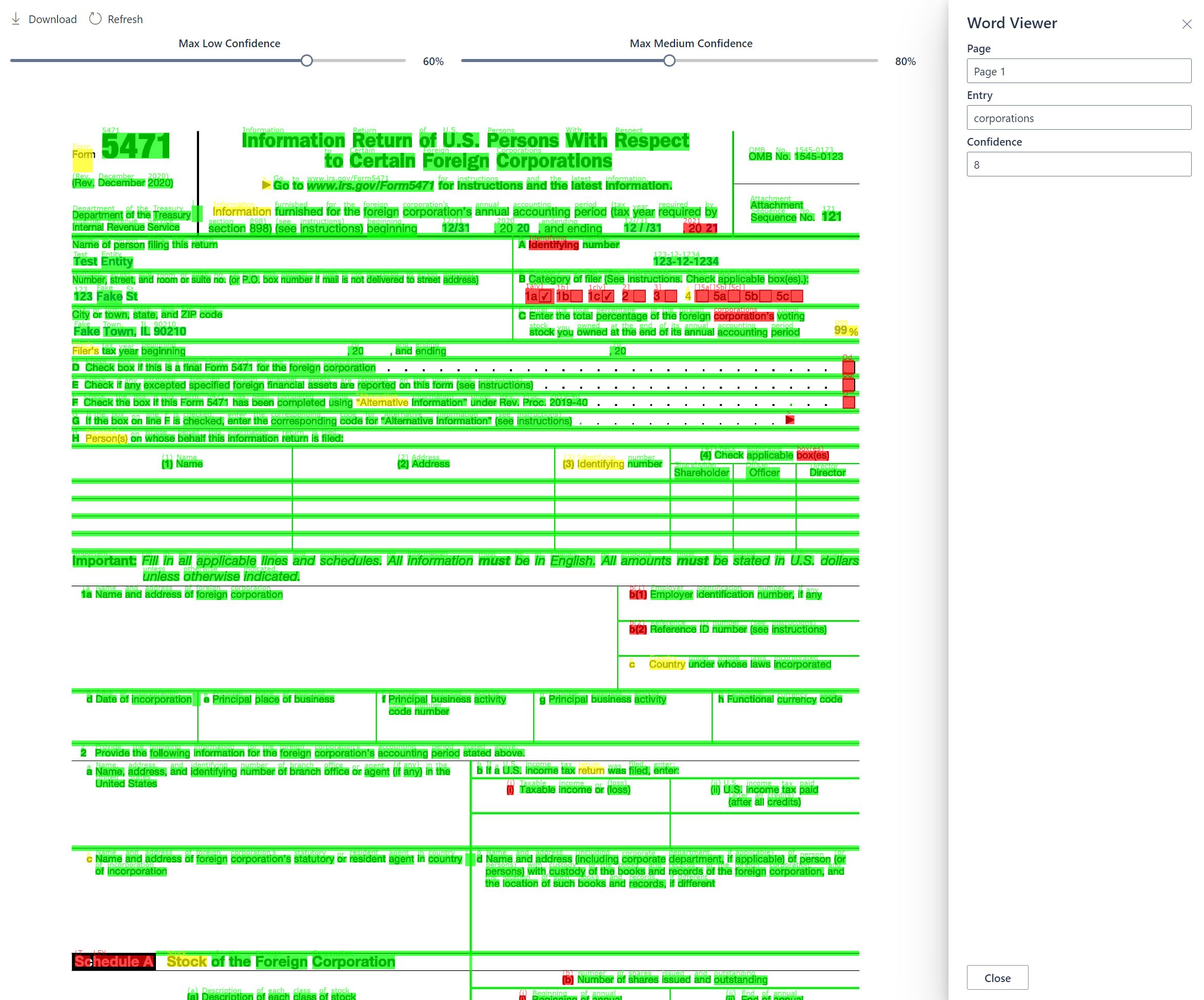
In addition, a validation screen has been created allowing users to validate OCR results via an easy to use UI. A toggle has been provided so a user can toggle their desired confidence levels and the associated color coding is changed on the fly. The original image has results overlayed and color-coded green, yellow, or red based on whether they are high, medium, or low confidence results. This output is written to a canvas element for rendering.
I currently do not have a demo hosted, though everything is available via my GitHub. I’ve also included a CodeFormation template to ease the creation of the various related AWS services required for hosting. Enjoy!